前回はcsvファイルをグラフ化するところまでやりました('ω')ノ
今回はデータを高速フーリエ変換(FFT)していきたいと思います('ω')ノ
FFTのコードはこちらです。scipyのfft関数を使います('ω')ノ
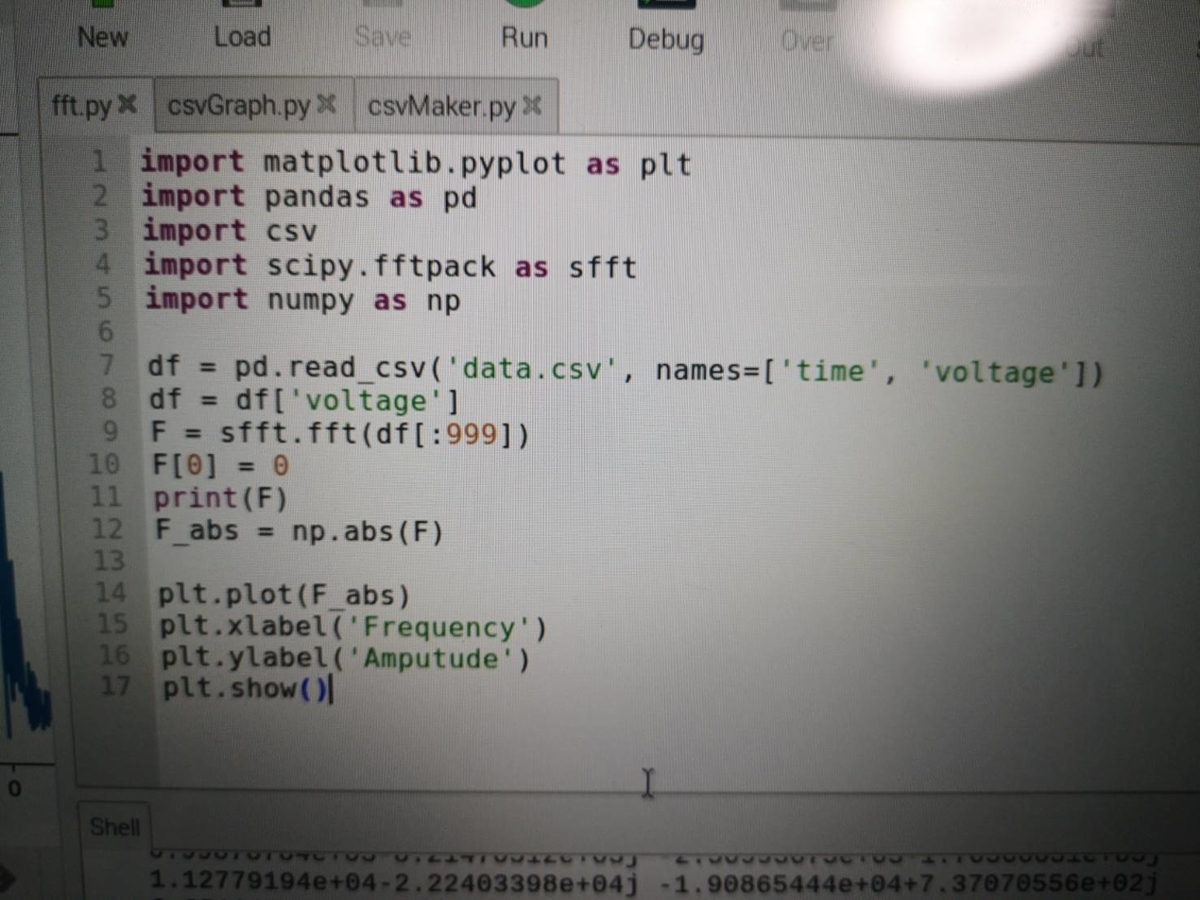
df = pd.read_csv('ファイル名', names=['time', 'voltage']) でcsvファイルを読み込みます
フーリエ変換したい方のvoltageの列をdfとします
F = sfft.fft(df[:999]) で信号dfに対する999点の離散フーリエ変換をFFTで計算します
実行するとこんなグラフが出ます
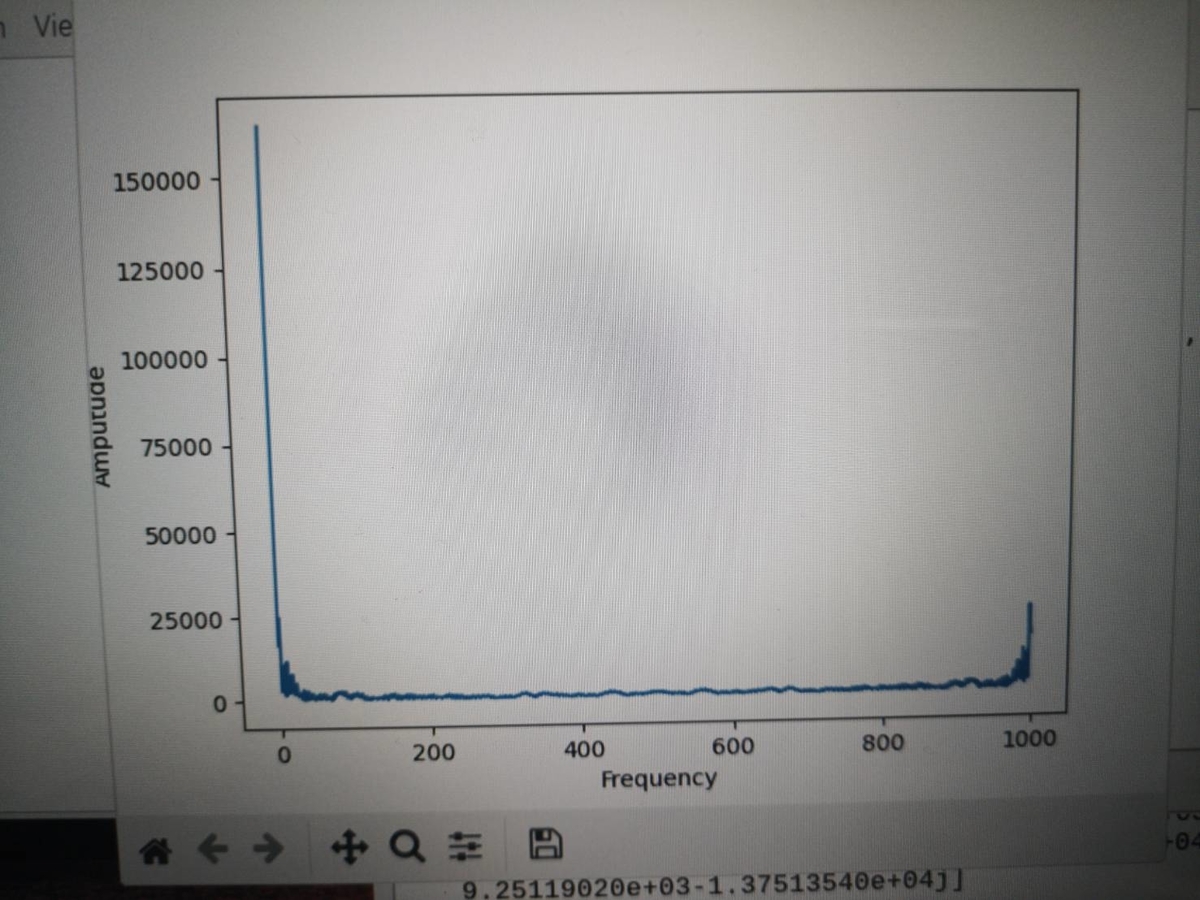
0Hzの所にピークが来ています
DC成分でしょうか??なんかしら影響が出てしまっているのかと思います。。
とりあえずF[0]=0 として0Hzの成分を0にします
その時のグラフがこちら('ω')ノ
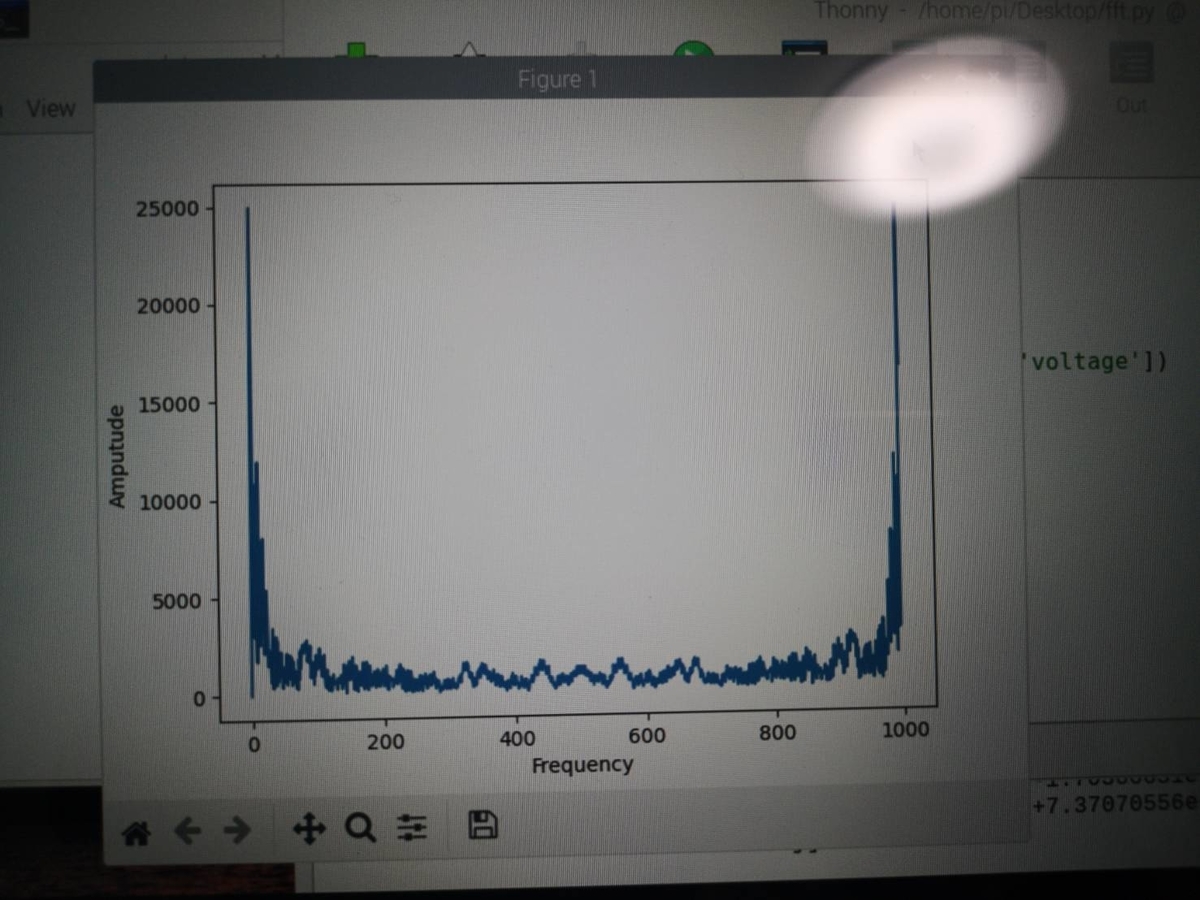
左右対称のグラフが出てきました('ω')ノ
F_abs = np.abs(F) は999個のデータからなるベクトルで、499を中心に線対称です
スペクトルは信号の周波数成分の大きさを表します
ここでのサンプリング周波数は1000Hzなので、ナイキスト周波数は500Hzです
F[0]からF[499]までの499個の間隔で500Hzを表します
どこの山が大きいのか見てみたいと思います('ω')ノ
nonzero()関数で欲しいインデックスを取得します('ω')ノ
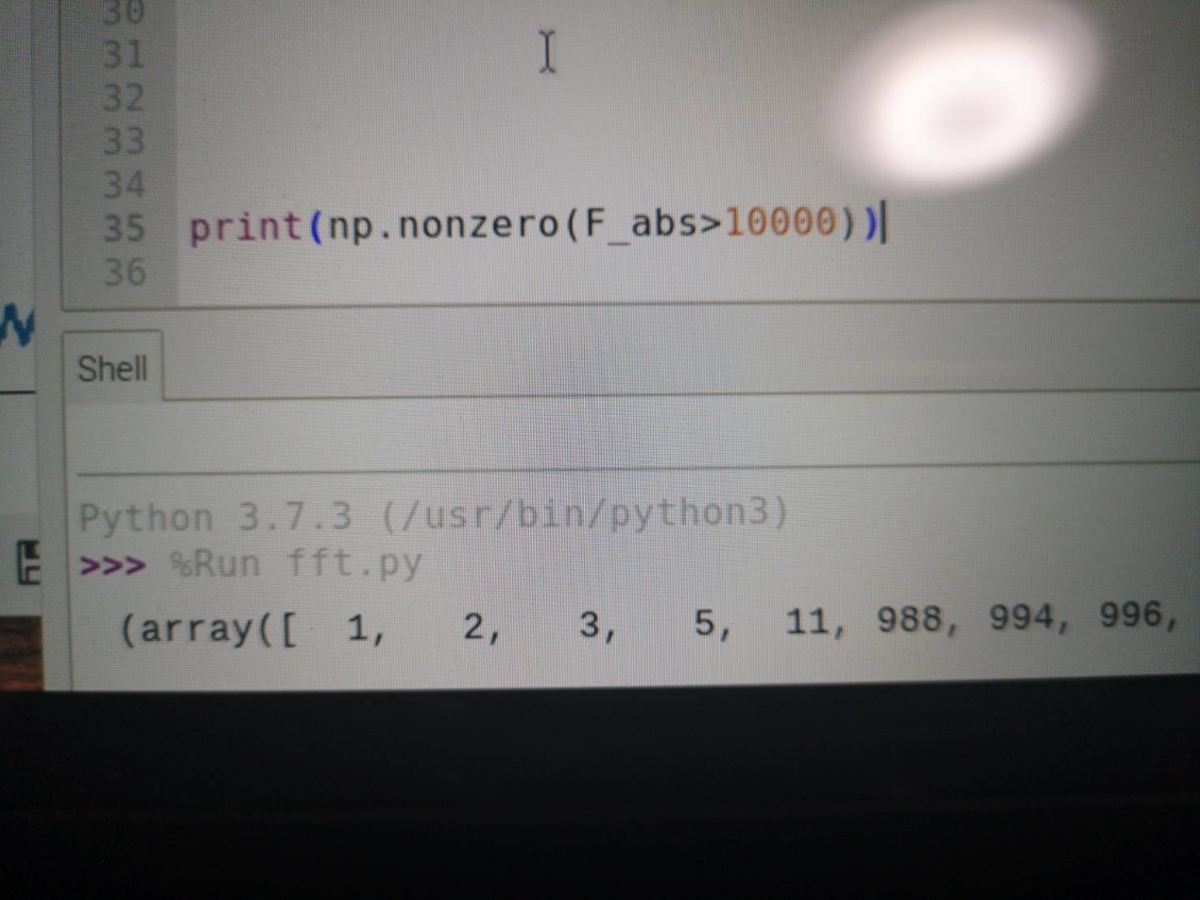
10000よりも大きいものを抽出してみました
1、2、3、5番の周波数の成分があることがわかります('ω')ノ
今回は適当なデータを使いましたが、次回は分類してみたいと思います('ω')ノ